The wisdom of crowds, and when it isn't
From Galton's ox to Polymarket — why aggregation works, when it fails, and the case for free voting
An ox at Plymouth, 1906
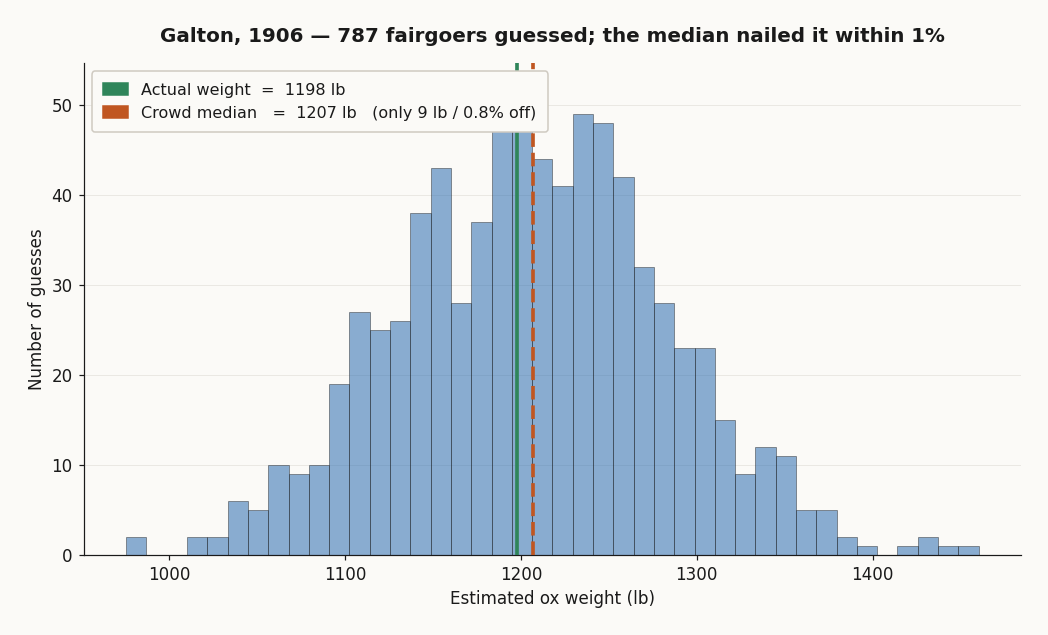
In 1906 Francis Galton — geographer, statistician, and unrepentant eugenicist — went to a country fair in Plymouth. The West of England Fat Stock and Poultry Exhibition was running a weight-judging competition: pay sixpence, write your guess on a stamped card, win a prize if you came closest to the dressed weight of a particular ox. 787 fairgoers paid the sixpence and wrote a guess.
Galton, who privately suspected this would be an excellent demonstration of the dumbness of the average voter, collected all 787 cards and worked the numbers.
The median estimate was 1207 pounds. The actual dressed weight came in at 1198 pounds. The crowd was off by nine pounds — eight tenths of one percent. He wrote it up for Nature in 1907 under the title Vox Populi, honest enough to publish the result that contradicted his hypothesis. A scattered, opinionated, often ignorant crowd had outperformed the bookmakers and the cattle experts.
Almost a hundred years later, James Surowiecki picked up the same observation and built The Wisdom of Crowds (2004) around it. His four conditions are still the cleanest way to think about when to trust a crowd.
The four conditions
A crowd is wise when four things are true at the same time.
Diversity of opinion. Each member brings something different — different experience, priors, blind spots. Errors in one direction get cancelled by errors in another, so the central estimate converges on truth. Homogeneous crowds (everyone read the same Twitter thread) just amplify whatever bias they share.
Independence. People form opinions on their own, not by copying. The moment opinions chain — "everyone seems to think X, so X must be right" — diversity collapses inward, and you stop having 787 estimates and start having one estimate repeated 787 times.
Decentralization. No central planner orchestrates inputs. Local knowledge — the farmer who watches the ox eat, the butcher who's dressed twenty oxen this season — gets a chance to enter the average. Centralized expertise misses what's in nobody's job description.
Aggregation. There's a mechanism to combine the inputs. The market price. The median. The vote tally. Without this, all the diversity and independence in the world produces 787 sticky notes that nobody reads.
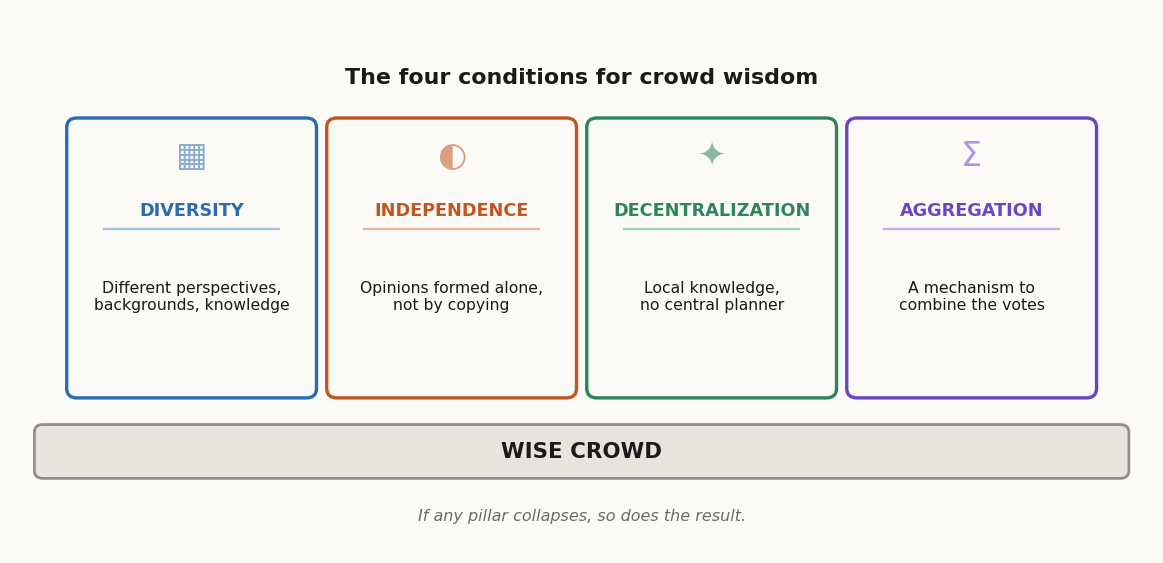
If any of the four collapses, the crowd stops being wise. That's both the promise and the warning: it's a fragile equilibrium.
When it actually works
Galton's ox isn't a one-off. Crowd aggregation has a strong empirical track record on tasks that fit the four conditions.
Who Wants to Be a Millionaire. When contestants used the "ask the audience" lifeline, the audience's plurality answer was correct around 91% of the time across the show's run. The "phone a friend" lifeline — one carefully chosen expert — clocked in around 65%. One person, even a smart one, against several hundred semi-distracted strangers in a TV studio, and the strangers won 9 times out of 10.
Wikipedia. No expert reviews each edit. Millions of pseudonymous contributors with diverse backgrounds independently apply local knowledge, with the diff log + revert mechanic acting as the aggregation step. The result is, on most topics, more accurate than the encyclopedias staffed by paid experts that it replaced.
PageRank. Larry Page's 1996 insight: rank web pages by counting incoming links from other pages, weighted recursively. Each link is a tiny implicit vote of confidence. The aggregate beat hand-curated directories like early Yahoo. Even today, link signals are still in the search-ranking mix.
Bird flocks and ant colonies. Not human crowds, but the same mathematics. Each individual follows simple rules with local information; the global behavior is more sophisticated than any individual could plan.
The pattern: many independent inputs, each carrying a small piece of true signal, get averaged into something accurate.
When the crowd gets dumb
The four conditions are easy to break, and the failure modes are well-documented.
Information cascades. Person 1 sees a private signal and decides. Person 2 sees that decision plus a private signal and decides. Person 3 sees two prior decisions and one private signal; if the prior decisions look unanimous, Person 3 may rationally ignore their own signal and copy. By Person 8 nobody is using their own information — everyone is using everyone else's. The crowd is now one decision repeated, and if the first signal was wrong, the entire cascade is wrong.

Groupthink. Same problem when independence collapses inside a small in-group. Boards of directors, panel meetings, group chats: dissent gets socially expensive, the loudest member sets the frame, the rest update toward the frame whether or not they agree. The famous social-psychology cases — the Bay of Pigs, the Challenger launch decision — fit this template.
Herding. A 2018 Nature Human Behaviour paper showed that copying behavior increases sharply with task difficulty and group size. The harder the question and the bigger the crowd, the more individuals throw their own knowledge over the side and lock onto whatever the visible majority is doing. Exactly when independent inputs would matter most, they evaporate.
Bubbles. Tulip mania, dotcom 2000, GameStop 2021: not stupid people, just smart people in an environment where independence has been destroyed by social proof and rapid feedback. The price stops being an aggregation of beliefs about fundamentals and becomes an aggregation of beliefs about what other people will believe tomorrow. That's a recipe for divergence, not convergence.
The mitigations are structural: collect individual estimates before deliberation, use blind voting before discussion, reward dissent explicitly, aggregate by median (resists outliers) rather than mean, and surface the distribution alongside the central estimate so people see the disagreement.
Polymarket and Kalshi: skin in the game
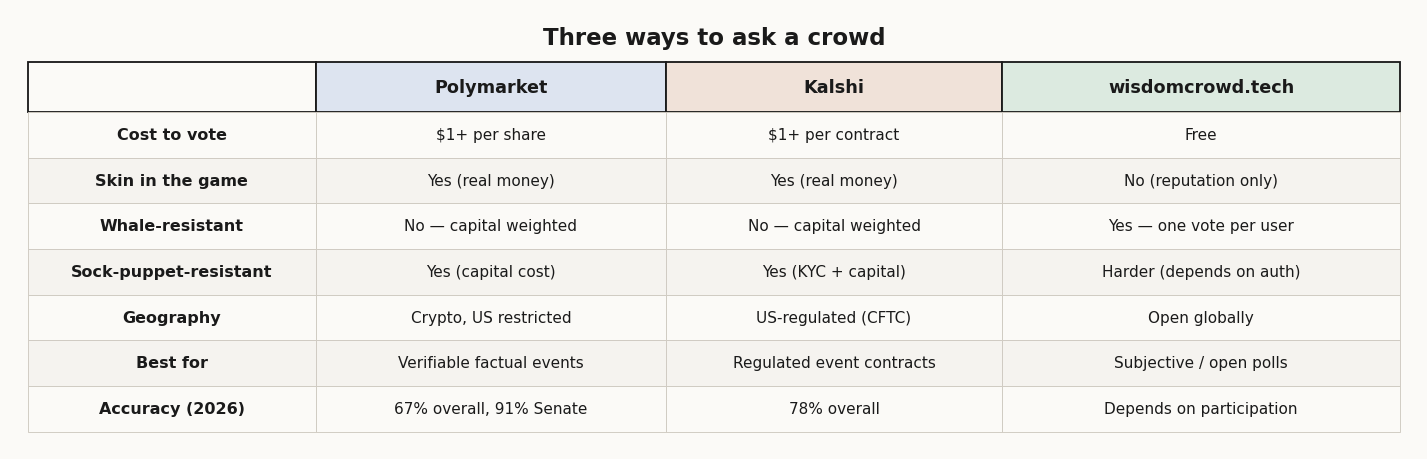
Surowiecki's 2004 book pre-dates the modern prediction-market boom. The current poster children are Polymarket (crypto-settled, USDC-based, accessible globally where it isn't blocked) and Kalshi (CFTC-regulated event contracts, US-based). Both ask the same fundamental question: what does the market think the probability of an event is?
The mechanism: traders buy and sell shares that pay $1 if an event happens, $0 if it doesn't. The price clears around the implied probability. A share trading at 67¢ means the market collectively prices the event at roughly 67% likely.
Why this works in theory: money is the strongest possible filter against noise. If you really believe the market is wrong, you have a financial incentive to correct it; if you don't believe it strongly enough to risk capital, you stay out. The result is that the marginal price reflects only the opinions of people informed and convicted enough to act on them. That's not the wisdom of the crowd — it's the wisdom of the informed crowd, which is a different thing.
The 2026 evidence is mixed:
Polymarket called 31 of 34 Senate races correctly in the 2026 midterms — 91% accuracy, well ahead of mainstream polling.
A Vanderbilt study, however, found that across all events Polymarket only got 67% of markets right, Kalshi 78%, and PredictIt 93%.
A London Business School + Yale paper analyzed 1.72 million Polymarket accounts and concluded that 3–4% of traders account for most of the price discovery — the wisdom isn't in the crowd, it's in a small minority of informed bettors who happen to use the market as their aggregation venue.
Translated: prediction markets work, but the four conditions don't quite hold the way the marketing copy says. Diversity is partial — capital is concentrated. Independence is partial — late traders see the price and condition on it. Decentralization is real. Aggregation is the strongest part — that's literally what the price is.
That's not a failure. It's a useful redefinition: prediction markets aggregate the views of people willing to bet, weighted by how much they bet. That's a different epistemic object from "the wisdom of the crowd," and worth knowing the difference.
wisdomcrowd.tech: the crowd without money
Prediction markets answer one kind of question very well: factual events with a verifiable outcome and a defined deadline, where there's enough liquidity to attract informed money. They are bad at — or simply can't run — a different kind of question.
What's the best Pixar movie? Should the project budget go into feature X or Y? Is this open-source library worth depending on for the next five years? What's a fair starting offer for this used car? Should I take this job?
These have no clean payout, no settlement date, often no objective truth. Putting money on them either doesn't make sense or distorts the answers — people bet on what they think the market will say, not what they actually believe.
wisdomcrowd.tech takes the other route: free to vote, no money, one person one vote. The whole point is to ask questions where the right model is "many people, each forming an opinion on their own, and we just want the distribution."
How it stacks up against the four conditions:
Diversity: depends on who shows up — globally accessible (no KYC, no payment rail, no regulator), so the upper bound is high.
Independence: a known weak point if the live distribution is shown before voting (visible consensus → cascade). Mitigation patterns: hide the distribution until vote committed, reveal only after deadline.
Decentralization: no central authority, no expert panel.
Aggregation: straightforward — count the votes, present the distribution.
The honest tradeoff vs. prediction markets:
A free-vote system gives up the noise filter that money provides — it's much easier to be loud without conviction. Sock puppets, bot accounts, brigading: real problems that a $1-per-share floor naturally suppresses. Free-vote systems compensate with auth (one account = one vote), rate limits, and after-the-fact analysis of suspicious patterns.
What it gains: questions you literally cannot price (subjective, ethical, internal team decisions, anything where the audience can't legally bet) become tractable. And it doesn't gate participation by capital — the immigrant nurse with an opinion about the city's housing policy gets the same vote as the hedge-fund manager. That's a different epistemic object too, and on the right kind of question, the better one.
When to use which
Three systems, three jobs.
Factual question, verifiable outcome, capital available → prediction market. Let money filter the noise. Polymarket if you want crypto-settled and global; Kalshi if you want regulated US contracts.
Subjective, moral, or no-payout question → free voting. Accept lower noise filtering, gain breadth and accessibility. wisdomcrowd.tech is built for this.
High-stakes decision in your team → blind individual estimates first, discussion second. Never raw show-of-hands; that maximizes herding. The Delphi method (anonymous rounds with feedback) is the disciplined version.
The misuse cases — the ones where crowds get blamed for being dumb — are almost always one of these:
Asking a market a question that's too far from any objective settlement, then surprise: traders price what other traders will price, not the underlying.
Asking a free-vote system a factual question that money would have filtered better, then surprise: 80% of respondents repeat what they heard from a friend who heard it from Twitter.
Running a "discussion" then a "vote" in that order, then surprise: the vote tracks the loudest discussant.
Galton's ox worked because every guess was independent, paid for, written down, and aggregated by the median — four conditions held by accident inside a 19th-century country fair. We can rebuild that today, but it takes design. The crowd is not a magic resource; it's a piece of infrastructure, and like all infrastructure it works only when you respect its tolerances.
Was this article helpful?
Comments
No comments yet.